
Chapter 5: Developing Evaluative Literacy Skills
Lisa Levesque

Overview
This chapter discusses evaluative literacy, or the skill of exercising critical judgment, as it relates to the Internet: using Web search tools and recognizing their flaws, recognizing the need to be critical online, and developing your ability to evaluate online information. It will discuss online hate speech and fake news as examples of why it is necessary to be aware of the inherent flaws in the ways that we access and evaluate information. It also provides a toolkit for evaluating information both online and offline.
Chapter Topics
-
- Introduction: Invisible Networks
- Web Searching: How Google Works
- How to Be Critical of Web Search Results
- The Almighty Click: The Internet and the Media
- Evaluation Toolkit
Learning Objectives
After completing this chapter, you should be able to:
- “Understand how information systems (i.e., collections of recorded information) are organized to provide access to relevant information” (ACRL, 2015, p. 22).
- “Formulate questions for research based on information gaps” (ACRL, 2015, p. 18).
- “Develop and maintain both an open mind [and a critical stance] when encountering varied and sometimes conflicting perspectives” (ACRL, 2015, p. 13).
- “Monitor [the information you gather] and assess [it] for gaps or weaknesses” (ACRL, 2015, p. 18).
- “Suspend judgment on the value of a particular piece of scholarship until the larger context for the scholarly conversation is better understood” (ACRL, 2015, p. 21).
Introduction: Invisible Networks
Everywhere we go, we are surrounded by invisible networks. The food we eat, the electricity we use, and the roads that we drive on are all small parts of the larger systems of agriculture, infrastructure, and transportation. Of course, you don’t have to be a farmer to appreciate an apple or an electrician to operate a light switch. However, part of being an informed citizen means gaining a basic appreciation for vast realms of knowledge, or systems—networks— that you will not likely master in their entireties. If you don’t become an electrician, you should still know enough about electrical wiring to avoid electrocuting yourself during minor home repairs.
The Internet is another invisible network. What makes the Internet unique is its defining role in shaping how we acquire information. Like turning on a light switch, using the Internet is deceptively simple. You don’t need to understand coding or hypertext protocol to update social media or search Wikipedia. These tools are designed to be simple. Safiya Noble, Librarian, Assistant Professor at the University of Southern California, and expert on biases in search engine algorithms writes, “When you go to Google, it’s just a simple box against a simple background. And that conveys, through its aesthetic, the idea that there’s nothing going on. Its design logic is so simple: type in a word, and you’ll get something back” (Noble & Roberts, 2018, para. 18). The simple design of tools like search engines hides how complex they truly are, and their own marketing often portrays them as answer machines. As Google writes on their webpage, “You want the answer, not billions of webpages” (Google, n.d., para. 1). Search engines cater to simplicity, and they work very hard to deliver the type of results that they believe users want to see.
This is not to say that using the Internet doesn’t require skill and literacy. As we discussed in chapter one, digital literacy and other associated literacies (such as media literacy and visual literacy) are essential for navigating the online world. In addition, Internet users are participants in shaping and creating the online information landscape. In order to be active, engaged, and discerning participants we have to use our judgment and be critical. In other words, we must develop .
Evaluative literacy means the ability to assess information, especially by contextualizing, critiquing, and confirming its truthfulness. Evaluative literacy means developing the ability to think critically: to know that you are a participant in a network larger than yourself. When confronted with a simple answer from a simple search box, be critical. This type of literacy will make you a more savvy digital citizen, able to identify bad information and seek out better, more substantiated facts. It will also improve your other literacy skills, making you a more informed contributor to online communities and a more critical consumer of media.
or literacy about one’s own literacy, contributes to evaluative literacy by allowing you to spot the gaps in your knowledge. Mackey and Jacobson define metaliteracy in this way:
To be metaliterate requires individuals to understand their existing literacy strengths and areas for improvement and make decisions about their learning. The ability to critically self-assess different competencies and to recognize one’s need for integrated literacies in today’s information environments is a metaliteracy. (Mackey & Jacobson, 2014, p. 2)
Metaliteracy requires curiosity and a little humility: recognize what you don’t know about a topic, then be willing to learn more and correct your understanding.
This chapter will cover the basics of online information networks, namely search engines and bias in digital information. From there, it will discuss how to develop evaluative literacy and metaliteracy skills in order to interact with this network. By learning more about what is often unconscious and unquestioned, we can all become more aware digital citizens.
Web Searching: How Google Works
Search engines are essential tools for navigating the Internet. They make the vast number of websites that are available online quickly accessible to searchers. Although it’s possible to use the Internet by typing in direct addresses, search engines are the predominant way that most Internet users conduct online research (Forrester, 2016). Understanding how they work is an important first step in understanding how information is organized and accessed online and how we interact with it. As Alexander Halavais, Associate Professor of Sociology (Arizona State University) and former President of the Association of Internet Researchers writes, search engines are “of interest not only to technologists and marketers, but to anyone who wants to understand how we make sense of a newly networked world” (2009, p. 1). It is important to view them not as “an object of truth” but as tools with specific design strengths and flaws (Halavais, 2009, p. 1-2).
Although there are differences between competing search engines, they all work in essentially the same way. The search engine sends out an automatic search tool, called a , crawler, or robot to investigate publicly available webpages. The spider, essentially a small snippet of code, travels via links, compiling information that it finds about webpages into a search engine index. When you enter a search into a search engine, your query is run against the index and search results are produced using a complex algorithm. The job of this algorithm is to to match your keywords to relevant web pages and give you the results it thinks you want to see.
These three elements, , , and , are all essential to the speed and success of search engines. Spiders automate data collection and retrieve information faster than any human ever could, meaning that search results can keep pace with frequently updated websites. The index enables quick information retrieval. Think how long each search would take if, instead of referring to an index, search engines had to check each query against each webpage individually. The Web would grind to a halt due to the increase in traffic alone. The algorithm increases relevancy, reducing the amount of time that a searcher must spend sorting through results to find an answer. The more relevant a search engine can make the results, the more satisfied the searcher, the logic goes.
Did You Know?
A website is a collection of webpages. For instance, the Ryerson University website http://www.ryerson.ca/ contains the “About” webpage, http://www.ryerson.ca/about/, the Campus Life webpage, https://www.ryerson.ca/campus-life/, and so on.
While there are a number of major search engines, such as Bing and Yahoo, none are as prominent as Google. Since approximately 2006, Google has held the majority market share of search engine use* (Google Gains Search Market Share), producing increasingly large revenues year after year and establishing itself as the “dominant” search engine in North America* (Frommer, 2014). To argue for its dominance and “monopoly status,” Safiya Noble cites noted academic researchers Siva Vaidhyanathan, Elad Segev, and the US Senate Judiciary Committee Subcommittee on Antitrust Competition Policy and Consumer Rights (Noble, 2018, p. 26-28, 36). As of February 2017, as Figure 5.1 below shows, Google holds the majority market share on all device types, far outstripping its competitors. Due to Google’s dominance, competing search engines have copied much of Google’s functionality. This means that learning about Google is a good way to learn about Web searching generally. This chapter focuses primarily on Google because its lead role in functionality and market dominance means that it is simply more important at the current time than other search engines. If search engines were bodies of water, some would be the Great Lakes or the Baltic Sea; Google is the Atlantic Ocean.
*An important exception to Google’s dominance: Google is blocked in China and so is superseded in that market by search engines that operate there, such as Baidu.

Google’s dominance can be traced back in part to its first early success. was developed by Google founders Sergey Brin and Lawrence Page (1998) while they were at Stanford. This algorithm ranks websites based on how many other sites link to it. The more , or links to a website, the higher the ranking; much like in high school elections, popularity is key for rising to the top. The logic is that the more popular a site, the more relevant it will be to a searcher. PageRank has been an exceedingly influential idea, establishing Google’s early success and influencing its competitors and shifting the focus of web search engines to focus on relevancy.
Activity 5.1: Inlinks and PageRank
A number of tools exist to analyze web traffic statistics and inlinks, including Moz Open Site Explorer and Alexa. Try using one of these tools (you may have to create an account) to view inlinks, traffic, and rankings for a website such as https://www.nytimes.com. While Google’s algorithm might be hidden from view, many aspects of Web searching are verifiable through empirical tests.
Key Takeaways
Linking to a site is like voting for it, according to search algorithms that take inlinks into account. It is best to avoid linking to any site, online post, or publication if you do not want to contribute to its success.
In Google’s current algorithm, PageRank remains an important part of the overall structure (Luh, Yang, & Huang, 2016), but it is just one algorithm that is used in conjunction with hundreds of other factors. For Google as well as for other search engines, webpage characteristics that will lead to higher ranking include the number of times a search term appears on a given webpage, where it appears on the webpage, the currency of the webpage or when it was last updated, and the page load time. Information about the searcher is also included in determining the relevance of results generated, including the searcher’s location and information pulled from past search history. This search history is drawn from Google account information, such as Gmail; this is the same with Microsoft account information for Bing; and with other accounts for their related search engines. Browser cookies will also store information that a search engine can draw upon. Browsers can store information about users’ online activity even when they are not searching or using search accounts. Using “incognito” or a private browsing mode limits the amount of information collected but does not stop browsers from storing personal information entirely.
Of course, not all of the factors of Google’s algorithm can be determined. While diligent Internet researchers have deciphered aspects of the algorithm, and Google has published some (see Google’s “How Search Works”), the exact formulation remains a well-guarded, multi-billion-dollar secret. The algorithm as it currently exists is incredibly complex, with algorithms inside algorithms and many complicated factors that impact one another. These include algorithms like RankBrain, which determines the intent of a searcher to assess relevance; to do this, it uses artificial intelligence, also called machine learning or deep learning. The algorithm learns about the searcher’s intent by processing large amounts of data. The strength of artificial intelligence systems is that they can process more data than humans ever could (Metz, 2016). A search engine like Google is what is known in computing as a , meaning that its mechanisms for determining results are not visible, and it is impossible to know exactly why it spits out the answers that it does. This has always been true for the general searcher, and now, due to advances in artificial intelligence, even the engineers who designed the algorithm would struggle to fully explain why a search produces the results it does.
There are a few major characteristics built into web searching, as described here, that all researchers should be aware of. A few examples are: web search results only include publicly accessible information, with emphasis placed on the more popular results; more recent information is more likely to appear than older information; and, results will be different depending on who is searching and where. Websites that have been optimized for web publishing will also appear higher in result sets and be more easily searchable, a practice called . While websites that are run on a small budget might have excellent SEO, websites whose creators have a larger budget are far more likely to have had time and money invested in improving their SEO. As a result, the structure of Web searching favours more commercial sites, which make up a large amount of Web content to begin with.
Did You Know
Google’s unofficial motto is “Don’t be evil.” It was their official motto, included in their Corporate Code of Conduct, until 2015 (Bock, 2011). It might be surprising to see the word evil in a company statement. But if Google intended to do evil they could do so: they hold a huge amount of power in providing access (or not) to the world’s information. In contrast, Google’s mission statement is: “to organize the world’s information and make it universally accessible and useful.” If universal access to information is a noble goal, as most of us would agree it is, then this one company holds the potential for both incredible good and incredible evil.
Related Articles
To learn more about algorithms, have a look at the Microsoft Research Lab’s Critical Algorithm Studies reading list (Gillespie & Seaver, 2016).
To learn more about PageRank, see the Wikipedia entry on this topic, which gives a basic overview and compares it to other ranking algorithms (Wikipedia contributors, 2019). The Wikipedia article on PageRank will likely also be updated should Google stop using PageRank to determine search results. Since Wikipedia can be edited by anyone at any time, this is a good opportunity to practice reading with a critical eye.
How to Be Critical of Web Search Results
Learning about the structure of Web search engines is the first step towards being critical of them: seeing their strengths, flaws, and inherent biases. The individual structure of the different search engines means that some handle queries better than others. For example, if you were to search for “sushi,” Google might return results for restaurant locations, ratings, and even directions to nearby spots. These results would be relevant if you were looking for somewhere to eat. They would be less relevant if you were looking for sushi recipes, or the history of sushi. For that, you would need to add more keywords and adjust your search.
Activity 5.2: Comparing Different Search Engines
Examine the search results for “sushi” in different search engines.
- Search for “sushi” in three different search engines: Google, Duck Duck Go, and Ask.
- Compare the first page of results. How are they the same? What’s different?
- Do all three sets of results include information that is specific to your location? Why?
- How many of the first-page search results are commercial (related to buying and selling) in nature?
In completing the activity above, you might have noticed a distinction between the way that commercial and non-commercial websites appear in search results. To put it plainly, there is a lot of content that exists online for commercial purposes. These results, due in part to good SEO, often rise to the top. The search engine interface can enhance the focus on commercialism. A number of Web search engines, including Google, have ads appear on their first page of results, and it can be difficult for searchers to distinguish advertisements from results. The majority of Google’s revenue is derived from advertising (Alba, 2017), a fact that is worth keeping in mind when assessing the prominence of ads in the interface design and when considering the design of its algorithm.
In Google, the default search-result set for “sushi” is nearby restaurant information, as Google has determined that this is the most relevant information for most users. This sushi search is a benign, if consumerist, example of how search engines privilege some kinds of information over others. To see less benign examples, look to more controversial kinds of information. When a search for geographic information is performed in Google, Google maps are often the first result. The Google map depictions of politically disputed borders, such as those between Israel and Palestine or between China and Tibet, will reflect the delineations accepted by the government of the country where the search is being run. Someone searching for information in Israel will see different borders than someone in Palestine would, thus, in a sense, seeing an alternate version of the world. Google claims they attempt to remain neutral, when possible, practising “agnostic cartography,” but Google also follows the laws of countries in which it operates (Usborne, 2016). If a government states that it is illegal to depict borders in a specific way, or even to share information about an occupied territory, then the local version of Google will comply.
Key Takeaways
Popularity is not the same as authority or credibility, and Web search results will reflect cultural bias.
Border disputes are a classic example of how Google skews information, but there are countless others. Algorithmic bias expert Safiya Noble (2016) does an excellent job of describing problematic Google searches related to race and gender. Since Google privileges popular, current, and algorithmically tailored information, its results often reflect, and even amplify, dominant cultural ideas, including racism and sexism. In the linked video below, Noble describes how racism and sexism are present in search engine auto-corrections, biased search-result sets, and the privileging of false but popular information over fact. For instance, she describes how search results for Trayvon Martin center around the narrative of his death. This is upsetting because it paints an incomplete portrait of his life, as if he were only the victim of a racialized crime. Thinking about the search engine results for Trayvon Martin is a way to think about the holes that exist in the information that is available to us online. She also describes how Dylann Roof, the racist mass-shooter, found confirmation for his burgeoning white-supremacist beliefs through a hate site. By possessing a veneer of credibility and being first in the search result set for “black on white crime,” the site Roof found was able to perpetuate racist myths and inspire a killer. Unlike the classic reference tool of the encyclopedia, Google has no human editors fact-checking information, no balanced reporting, and no limitations on subjects like hate speech. An encyclopedia also doesn’t change based on the information that you have read previously, whereas Google relevancy ranking are always changing, giving searchers who look up racist content more of the same in later searches.
Have a look at this conference presentation by Safiya Noble at the Personal Democracy Forum 2016, entitled “Challenging the Algorithms of Oppression.” Copyright: Safiya Noble, Personal Democracy Forum.
Pause and Reflect
Safiya Noble’s video (2016) is disturbing for a number of reasons. It describes how the Internet is a powerful tool, but that it is important to remember that the information it contains is only a snippet of the information available in the world. It can be all too easy to be caught in an , an online setting that reaffirms your pre-existing biases without challenging your opinion or exposing you to new ideas. Echo chambers can be enabled by Web structures, such as Google’s algorithm, that are specifically designed to present information that it predicts you will find relevant.
These examples highlight some of the problems inherent in using search engines to find information. This is not to say that search engines are bad or that you should not use them. Instead, understand their biases and inherent limitations as a tool. Search engines like Google base their algorithms on the behaviour of searchers writ large and on the content that is available online. In this way, they reflect the society that has created them, often reaffirming systems of power— capitalism, dominant political regimes, and white supremacy. When assessing information, it is important to ask yourself: What is the , or overarching story, that is being told? Which voices are not being heard? We like to believe that the Internet is a place where all voices can be heard, but that is unfortunately not true. As Alexander Halavais (2009) writes, the information on the Web is not flat, or equal; it’s “chunky,” or arranged in such a way that the most popular sites and voices account for most of the traffic (p. 60). The design of search engines and relevancy ranking algorithms “increase the current imbalance” (p. 68). Even programmers at Google will admit that their designs contain societal bias, although they might be more likely to use a word like “fairness” to soften the blow (Lovejoy, 2018).
In addition to boosting popular sites and commonly held biases, the Internet is also a powerful tool for winning hearts and minds to extremist causes. Hate groups are on the rise in North America, and a cause according to experts is online recruitment. A systematic review of ten years of research on cyber-racism (Bliuc, Faulkner, Jakubowicz, & McGarty, 2018) found that “racist groups and individuals” share “remarkable creativity and level of skill in exploiting the affordances of modern technology to advance their goals,” which include recruitment, developing online hate communities, and spreading racist content (p. 85). In the global, digital world, “those with regressive political agendas rooted in white power connect across national boundaries via the Internet” (Daniels, 2012, p. 710). By contrast to the online world, you’re unlikely to encounter racist propaganda in most library or bookstore collections because items in these collections are carefully curated by human experts in the information field to exclude this content. In contrast, Internet searches are selected and filtered using a highly automated process.
As racist content is not filtered from searches, uncritical users can become easy targets for hate sites. An effect of the relevance that Google and other search engines focus so much on producing is that searchers are willing to trust these services to deliver results, a phenomenon that Indiana University librarian and ethnographer Andrew Asher calls “trust bias” (2015). In other words, searchers tend to trust search results unquestioningly because most of the time, they deliver. As a result, we are susceptible to them those times that they deliver poor results. Search results always need to be approached with a healthy amount of skepticism. It’s your job as a researcher to assess the information that an online search gives you and to know to look for bias. Keeping the structure of search engines like Google in mind will help you assess when and how it is an appropriate tool to use.
Pause and Reflect
Google claims to be neutral in the way that they collect and share information, but what is neutrality? It is always worth remembering that the algorithms Google and all other Web services rely upon were written by people, and people have their own inherent biases. From this perspective, all algorithms are a reflection of someone else’s idea of neutrality. Their idea of what is neutral may be different from yours or mine.
Related Articles
For more on the myth of black on white crime and how it is perpetuated through digital mediums, see the 2018 Southern Poverty Law Centre article, “The Biggest Lie in the White Supremacist Propaganda Playbook: Unraveling the Truth About ‘Black-on-White Crime.” It gives a history of this concept and makes the point that “The internet has made it immeasurably easier for white nationalists to gather, publish articles, discuss ideas and reach out to those like Roof who might be amenable to their messages” (Staff, 2018, para. 105).
The Almighty Click: The Internet and the Media
The connections between websites in the form of inlinks help shape the web by raising the findability of some types of content and diminishing that of others. However, you don’t need to be a Web editor to effect change. Even if you don’t use social media or have never written a blog, you have still helped shape the Internet just by being a consumer of content. This is because search engines are dynamic and reactive. Every click you give to a webpage contributes to its traffic rank and popularity. Clicks are a major contributing factor to the search engine ranking of every website, from Wikipedia to the official website of the White House. Many sites, including reputable media websites like that of the New York Times, generate revenue from advertisements on their site and rely on that advertising to remain in business. This is one reason exists: even though clickbait content is usually disappointing, the headline is so intriguing that clickbait articles get traffic, and traffic means revenue from advertising.
As a result, the types of websites that receive clicks are the types of websites that thrive. Consider the phenomenon known as , anxiety produced by searching for medical information online. A 2009 study by White and Horvitz describes how “web search engines have the potential to escalate medical concerns.” This is because a search for a term like “chest pain” will give results for serious medical conditions, such as heart attacks. Fearing the worst, users are likely to click on results related to these more serious conditions. These clicks then shape the structure of the web, meaning that a search for chest pain will rank results for heart attacks higher than other, less serious conditions. It is a vicious cycle of medical search anxiety that causes most searchers who look for benign conditions to conclude that their death is imminent.
One of the largest effects has been the recent phenomenon of , a term that increased in popularity in 2016 during the United States presidential campaign and election. Misinformation has always existed—think of the old adage that history is written by the victors—but fake news is a distinct, contemporary version of misinformation. The exchange of clicks for cash has had a major influence on online media, as discussed in chapter 2. For example, online news readers might skim headlines that appear from news sites, like Facebook or Flipboard, without paying attention to the author or information source. Fake news usually focuses on topical content that is sensational or emotional, such as a breaking election story. This type of content demands a quick read and response, rather than an in-depth analysis. Fake news relies on the format of online news to be successful: it is easily accessed, skimmed, and shared. However, it also draws deeply on essential flaws in human behaviour. It appeals to our emotions, and we are less likely to be critical when emotionally affected. And, when news fits our pre-existing beliefs and biases, we are less likely to question it. In psychology, this is called . Fake news succeeds because it is scintillating and emotionally appealing. Like alarming medical information, fake news feeds on its own popularity. The more it is clicked on, the more popular it grows.
Fake news also succeeds because of our very human preference for convenience. It’s easy to read the headlines. It’s much more intellectually difficult and time consuming to think critically, do in-depth research, and question sources on a regular basis. Yet this is what is required to be a responsible digital citizen and an effective researcher. The more you are aware of the biases that exist in digital information systems as well as your own biases and emotional blind spots, the better equipped you will be to counteract bias of all types.
Evaluation Toolkit
Up to this point, this chapter has addressed how to be critical of search results. The focus will now shift to evaluating online sources themselves. The reason for this is until we as a society can reinvent Google or limit the amount of hate speech and other misinformation online – complicated goals – our own best line of defence against poor information is ourselves. Developing evaluative literacy is essential for protecting ourselves from poor information, and the best way to develop it is to practise on a regular basis. Question the author you are reading. Question their research methods. Question the publications they write in, and question their reason for writing. Experts, well-founded research, and credible publications can all stand up to this kind of scrutiny. Being inquisitive is the best form of defence against misinformation.
Of course, it’s also helpful to have a toolkit at the ready to help you decide what information is valuable and what is not. The following toolkit is broken into two parts: evaluating all types of information, and evaluating digital information.
Evaluating All Types of Information
A classic tool that can be used to evaluate any kind of information (both online and offline), including academic and popular, physical and digital sources, is the PARCA test. This tool can be used to help you identify a resource’s strengths, weaknesses, and biases. The PARCA test can be used for in-depth evaluation, but it can also be used as a quick exercise once you are familiar with the test and once critical questioning has become an ingrained practice for you.
PARCA stands for purpose, accuracy, relevancy, currency, and authority.
- Purpose
- What is the author’s purpose in writing?
- Who is the intended audience?
- What is the central argument? What are its implications?
- Is the author participating in a larger conversation about this topic?
- Accuracy
- Does the author use accurate evidence to support the argument?
- If so, can you verify this evidence?
- Does the publication have measures in place to improve accuracy, such as a peer-review process?
- Can you distinguish between the facts being presented and the author’s opinion on them?
- Relevancy
- Is this work relevant to your research question?
- How would you use this work in your own writing or creation?
- Does the work come from a relevant discipline?
- Does the relevancy of this resource change your search strategy going forward?
- Currency
- When was this work published?
- Are the author’s facts current?
- If the author is writing about a particular time and place, have the circumstances changed?
- How important is currency to this field of study? For example, currency is very important for cutting-edge scientific research but can be less important for literary analysis.
- Authority
- What makes the author an authority on this subject? Consider credentials, experience including prior publications, identity, and any other indicators.
- Has the author published previously on this topic? When, and where?
- Is this a reputable publication?
- Does this work come from a mainstream or marginalized perspective?
Evaluating Digital Information
The PARCA test allows you to take an in-depth look at the content of a resource. But it doesn’t look closely at format and it doesn’t look outside the work to explore the larger context it exists within. The next two sections, “Technical Tools” and “Fact-Checking,” will help you do just that. Web publications and websites, ranging from New York Times articles to blog posts, are all the products of an online network and they must be read in this specific context.
Technical Tools
This list of tips should serve as a basic introduction to some characteristics specific to digital information. They aren’t hard-and-fast rules; for instance, a site that ends in .edu is normally affiliated with an educational institution, but this is not always the case. Online sources of misinformation will often copy the signs of legitimacy to blend in. As always, exercise critical thinking. In contrast to the PARCA test, using these tips is meant to be a quick and immediate form of evaluation.
- Check the URL: Legitimate news sources usually have a professional URL that matches the name of their organization. For instance, the website for CBC news is http://www.cbc.ca/news. Fake news URLs are less likely to be professional in nature or identifiable as a distinct news organization. They may have a URL that describes their mission statement and bias; they might also attempt to appear legitimate by adopting a formal name. Just because the site you are visiting has the word “Association” or Chronicle” in the title, that doesn’t mean it is legitimate; you may need to fact-check the site in more detail.
- Identify the top-level domain of the URL: The domain is the name of a website URL eg. www.cbc.ca. Each of the elements of this web address has a specific purpose. The “.ca” portion of this address is called the top level domain. Other common top level domains include “.com,” “.org” and “.edu.” It is easy to misread the top level domain. There is limited regulation around domain name registration, so a top-level domain such as .org that is conventionally used for not-for-profit organizations doesn’t guarantee that a site is actually a not-for-profit website. Fake news sites sometimes use URLs that mimic legitimate sites but use a different top-level domain: for instance, http://www.cbc.ca.co/news, where .co is the top-level domain. It’s the final .co that determines the website location, and this url has nothing to do with the site www.cbc.ca.
- Determine the nature of the site: Check for an About Us or Contact Us page. How does this website describe itself to the world? If they have a social media presence, how does this site present itself there? Look for keywords related to bias or statements that seem inflammatory or questionably factual.
- Analyze the quality of the web design: Examples of poor Web design include sites with too many colours or fonts, poor use of white space, and numerous animated gifs. Good Web design is a sign of credibility. A news organization like the CBC can afford to hire a Web designer (or in fact a team of Web designers); they cannot afford to have an unprofessional-looking website. This is not to say that all sites with good Web design are legitimate or vice versa. Plenty of objectionable sites may have the money to ensure they look good, and similarly, some admirable organizations don’t put enough money into a good-looking site; however, the overall visual impression you get from a site will usually tell you something about the intentions and focus of the organization.
- Check the article’s links: Are there any and do they work? How recent or up-to-date are they? The links that extend from one web page to another will tell you a lot about the political affiliation of that site and what the author considers authoritative. For instance, a right-leaning political site will likely link to other right-leaning political content. The Internet is one big web: what other strands of that web is your site connected to?
Fact-Checking
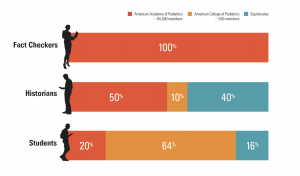
In a 2017 study at Stanford University, when participants were asked to compare two websites—that of the legitimate American Academy of Pediatrics and that of the homophobic splinter site the American College of Pediatricians—both historians and students performed poorly in comparison to fact-checkers (Wineburg and McGrew, 2017). The fact-checkers, in addition to soundly beating their peers at identifying the illegitimate site, were also more efficient with their time. This led the researchers to conclude that being able to fact-check and read laterally are essential skills when evaluating digital information. Reading laterally requires opening new tabs and searching for information about a resource or website, rather than reading the content on the site itself.
Fact-checking requires verifying through independent sources context for the source you are evaluating. Here are a few suggestions for learning about a source’s context:
- Learn more about the publication: There are many fact-checking websites that can help you verify an online story and learn about the reputation of a website. Two of the best-known and most reliable are factcheck.org and snopes.com. You can search these sites for verification about a questionable fact or information about a site. Searching for the name of a url in a search engine using quotations will also help you determine its reputation. Best of all, googling a url in quotation marks doesn’t give any clicks to sites that you would rather not visit.
- Triangulate the information: Read about a subject and verify the facts from a number of sources. Ideally, the sources you compare should have different perspectives and different purposes. To dig even deeper, determine where the facts originated. Are they from a direct source such as a study, report, or in-person investigation, or from somewhere else? Track down the primary document if possible. Is the primary document itself from a credible source, such as a well-known university or research group?
- Read up on the author: Read other works by the author and find out basic biographical information. This may reveal biases and objectives. For example, a journalist will have a different objective than a lobbyist. If the article has no attributed author, then this is a red flag that the article may be the product of a and might not be subject to editorial review.
- Research the images: If an image used in a news article looks suspicious to you, try using TinEye or Google Reverse Image Search to find out if the image has been used elsewhere. If the image is legitimate, searching for other images of the same scene might provide you with more context.
- Check who owns the domain: If you’re curious about who owns a website, try looking it up on WHOIS. For instance, a search for cbc.ca will show that it is owned by the Canadian Broadcasting Company, which is to be expected. Knowing who owns a domain can tell you a lot about the purpose of the site.
Pause and Reflect
Wineburg and McGrew (2017) use the term “” to describe reading about a source, like a webpage, rather than reading the source itself. However, there is more than one way to read across texts. Transliteracy is defined as “the practice of reading across a range of texts when the reader seamlessly switches between different platforms, modalities, types of reading, and genres” (Sukovic, 2016). Transliteracy is an essential skill for netchaining, which occurs when a reader follows links, citations, and ideas from one resource to another (Sukovic, 2016). Digital resources encourage transliteracy and netchaining through their interconnectedness, and lateral reading is an essential skill to evaluate information.
Activity 5.3: Test Yourself
- Before reading this chapter, what assumptions did you have about the structure of the Internet? How have those assumptions changed?
- Imagine that you have the job of creating a better search engine. How could you organize information in a way that does a better job of balancing what information rises to the top and what sinks to the bottom?
- This chapter listed some problems with Web searching, such as the bias towards foregrounding more recent information. Can you think of any other biases that exist in Web search results because of the structure of Web searching?
- If a government states that it is illegal to depict borders in a specific way, and Google Maps complies, is that giving in to censorship?
- Evaluate this website using fact-checking techniques: Who is the author, and what is his authority? Do you think this a reputable website? Why or why not?
- After you have fact-checked the site, assess this article from the site above using the PARCA test.
Resources
To check Web-traffic information:
- Alexa Website Traffic, Statistics and Analytics
- MOZ Open Site Explorer: link research and backlink checker
To fact-check online information:
To search for images, including descriptions and online locations:
To identify a domain owner
References
Alba, D. (2017). Google and Facebook still reign over digital advertising. Wired. Retrieved from: https://www.wired.com/story/google-facebook-online-ad-kings/
Armstrong, M. (2017, March 31). Google, Googler, Googlest. Statista. Retrieved from: https://www.statista.com/chart/8746/global-search-engine-market-share/. 2017.
Asher, A. D. (2015) Search Epistemology: Teaching students about information discovery. In T. A. Swanson & H. Jagman (Eds.), Not just where to click: Teaching students how to think about information. (pp. 139–154). Chicago, IL: Association of College and Research Libraries.
Bliuc, A., Faulkner, N., Jakubowicz, A., & McGarty, C. (2018). Online networks of racial hate: A systematic review of 10 years of research on cyber-racism. Computers in Human Behavior, 87, 75-86. doi:10.1016/j.chb.2018.05.026
Bock, L. (2011) Passion, not perks. Think with Google. Retrieved from https://www.thinkwithgoogle.com/marketing-resources/passion-not-perks/
Brin, S., & Page L. (1998). The anatomy of a large-scale hypertextual web search engine. Computer Networks and ISDN Systems, 30, 107–117. doi:10.1016/S0169-7552(98)00110-X
Caulfield, M. A. (2017). Web literacy for student fact-checkers. Pressbooks. Retrieved from https://webliteracy.pressbooks.com/
Daniels, J. (2013). Race and racism in internet studies: A review and critique. New Media & Society, 15(5), 695-719. doi:10.1177/1461444812462849
Forrester Research. (2016). Why search + social = success for brands: The role of search and social in the customer life cycle. Retrieved from: https://www.catalystdigital.com/wp-content/uploads/WhySearchPlusSocialEqualsSuccess-Catalyst.pdf
Framework for information literacy for higher education. (2015). Chicago: Association of College & Research Libraries. Retrieved from http://www.ala.org/acrl/standards/ilframework
Frommer, D. (2014, August 19). Google’s growth since its IPO is simply amazing. Quartz. Retrieved from
https://qz.com/252004/googles-growth-since-its-ipo-is-simply-amazing/
Gillespie, T., & Seaver, N. (2016, December 15). Critical algorithm studies: A reading list. Social Media Collective Research Blog. Retrieved from https://socialmediacollective.org/reading-lists/critical-algorithm-studies/
Google. Code of Conduct. Archived April 19, 2010. Retrieved from https://web.archive.org/web/20100419172019/https://investor.google.com/corporate/code-of-conduct.html
Google. (n.d.) How search works. Google Inside Search. Retrieved from https://www.google.com/search/howsearchworks/
Halavais, A. (2009). Search engine society. Cambridge, MA : Polity Press.
Lovejoy, J. (2018). Fair is not the default. Google Design. Retrieved from:https://design.google/library/fair-not-default/
Luh, C., Yang, S. & Huang, T. D. (2016). Estimating Google’s search engine ranking function from a search engine optimization perspective. Online Information Review, 40(2), 239-255.
Mackey, T. P., & Jacobson, T. E. (2014). Metaliteracy: Reinventing information literacy to empower learners. Chicago, IL: Neal-Schuman Publishers, Inc.
Metz, C. (2016, February 4). AI is transforming Google search. The rest of the web is next. Wired. Retrieved from: https://www.wired.com/2016/02/ai-is-changing-the-technology-behind-google-searches/. 2014.
Noble, S. (2016, June 15). Challenging the algorithms of oppression. Personal Democracy Forum (PDF). [Video File]. Retrieved from: https://www.youtube.com/watch?v=iRVZozEEWlE&feature=youtu.be
Noble, S. U. (2018). Algorithms of oppression: How search engines reinforce racism. New York, NY: New York University Press.
Noble, S. U., & Roberts, S. T. (2017, December). Engine failure: Safiya Umoja Noble and Sarah T. Roberts on the problems of platform capitalism. Logic, 3. Retrieved from: https://logicmag.io/03-engine-failure/
Staff, H. (2018). The biggest lie in the white supremacist propaganda playbook: Unraveling the truth about ‘black-on-white-crime. Southern Poverty Law Centre. Retrieved from https://www.splcenter.org/20180614/biggest-lie-white-supremacist-propaganda-playbook-unraveling-truth-about-%E2%80%98black-white-crime
Sukovic, S. (2016). Transliteracy in complex information environments. Amsterdam, MA: Chandos Publishing.
Usborne, S. (2016). Disputed territories: Where Google maps draws the line. The Guardian. Retrieved from http://www.theguardian.com/technology/shortcuts/2016/aug/10/google-maps-disputed-territories-palestineishere
White, R. W., Horvitz, E. (2008). Cyberchondria: Studies of the escalation of medical concerns in web search. Microsoft Research. Retrieved from https://www.microsoft.com/en-us/research/publication/cyberchondria-studies-of-the-escalation-of-medical-concerns-in-web-search/
Wikipedia contributors. (2019, July 26). PageRank. In Wikipedia, The Free Encyclopedia. Retrieved from https://en.wikipedia.org/w/index.php?title=PageRank&oldid=907975070
Wineburg, S., & McGrew, S. (2017). Lateral reading: Reading less and learning more when evaluating digital information. Stanford History Education Group Working Paper, 2017-A1. doi:10.2139/ssrn.3048994
Media Attributions
- Chapter Header Image © Hebi B
- Figure 5.1 Search Engine Global Market Share © Net Market Share is licensed under a CC BY-ND (Attribution NoDerivatives) license
- Figure 5.2 © Snopes is licensed under a All Rights Reserved license
- Figure 5.3 © Wineburg and McGrew, 2017. is licensed under a All Rights Reserved license
The ability to assess information, especially by contextualizing, critiquing, and confirming its truthfulness.
The ability to identify gaps in one’s own knowledge, understanding, or literacy skills.
Also called a crawler or a robot, this snippet of code is used by search engines to webpages and retrieve information for the index.
For search engines, an index is a collection of webpage information compiled by spiders and used to generate search results.
A set of rules used to calculate an answer to a query, or question. Web search engines use highly complex search algorithms.
An initial rule used in Google’s algorithm where webpage relevance is determined by inlinks.
A hyperlink connecting one webpage to another. If site A links to site B, that counts as one inlink for site B.
A way to describe a device that is characterized by its inputs and outputs and where the calculations at work are hidden. An algorithm is a kind of black box.
The practise of editing a website to improve Web search-result ranking.
An online environment that reinforces pre-existing biases and beliefs.
From postmodern theory, a grand, overarching story of the way the world functions, which is used to explain and justify; a narrative about narratives.
Online content with an intriguing title or pitch but insubstantial content. A product of the contemporary digital information environment.
Anxiety produced by browsing online medical information.
Misleading or biased information, usually political in nature, enabled by digital forms of information sharing.
A republisher of information originating from other sources. Republishers like Facebook use an algorithm to determine what content to display.
The tendency to selectively search for and interpret information in a way that confirms one’s own pre-existing beliefs and ideas.
A disreputable type of online publication where writers are often anonymous and content is produced quickly and often without verification of facts.
Fact-checking by reading contextually about a website.
